alastairp: Hi, I also checked out a few things this morning, and realized we could also use zstd with parquet for even better performance! (especially in the long run)
Pros:
- Parquet is future-proof with great support with pandas, spark, etc.
- It'll make the data ready to go for future use for ML, etc applications.
- It supports zstd as a compression too!
- Loading times are exceptionally faster, and sizes are ridiculously low, especially for text data.
- Even export times could be lowered since pandas has great support for parquet too
It performs great enough with gzip and snappy. It'll surely perform even better with zstd
darkstardevx joined the channel
monotux has quit
monotux joined the channel
BrainzGit
[bookbrainz-site] 14tr1ten opened pull request #858 (03new-creation-form…uf-edit-entity): Feat(route): Edit exisiting entity through unified form POST route https://github.com/metabrainz/bookbrainz-site/p...
aerozol
alastairp: did you still have some tickets coming my way?
reosarevok: mostly planning to write some normal JS ones where I feed some state into the reducer functions and check the output. but I'll try to add some basic Selenium ones too
Pratha-Fish
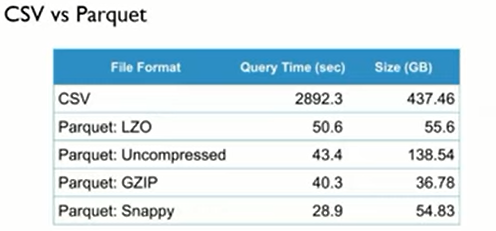
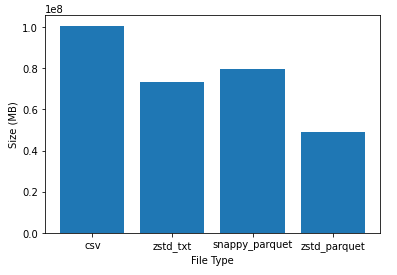
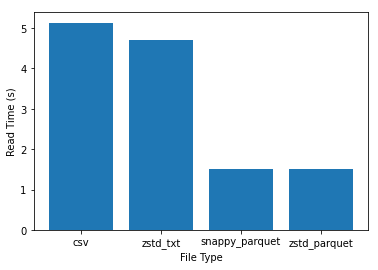
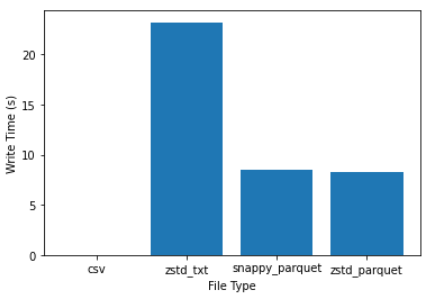
alastairp: Looks like parquet+zstd is acing every stat.
Excellent r/w time with the smallest storage size!
Also note that reading gzip > writing to txt.zst is ridiculously slow.
Maybe we should really shift to zst+parquet for all the data
reosarevok
bitmap: sounds good, at least to begin with :)
I'll do the beta thing and add more genre data, and then I'll look into the search changes yvanzo requested for the genre ws things :) Maybe we can release that when he's back
thanks bitmap for the comments on SQL, that's more or less what I expected
Pratha-Fish: thanks for the experiment, incredible to see how small and fast parquet is. you're right, this might be a good idea.
keep in mind that we also need a format that can be used by people no matter what programming language they use - let's have a discussion with lucifer about this, because we're saving space maybe we can distribute it in both formats
how are you writing csv/parquet? just with the DataFrame methods? for comparison, can you also do the same with csv+gz?
how many items did you write? because 22 seconds does seem like a lot, but I guess you're writing many files in a loop?
alastairp: hi! whats the data to be distributed here?
alastairp
hi lucifer
antlarr joined the channel
this is the music listen histories dataset. 27 billion rows, currently distributed as csv, 1 file per user. each row is timestamp, recording mbid, artist mbid, release mbid
we've already obtained a 50% filesize reduction by switching from gz to zstd, but the question is shoud we go further and use parquet as well, which gives additional size reductions as well as a significant speed increase when loading
lucifer
parquet is probably better in almost all ways with the exception of being not human readable and you can't edit it in excel.
but 27B rows is too much data for direct human consumption anyway so i think these issues don't matter much.
alastairp
yeah, right
so we read/write it in spark and python?
perhaps it'd be nice to be able to `cat file.parquet | to-csv` somehow, to be able to view the data as csv if necessary? I'm reading the internet and it seems to just suggest using pandas for this, which is ok but not great
lucifer
yes. both parquet and csv have built in support in spark. in python, you need to add pyarrow manually to use parquet (csv support is builtin as you know).
there's duckdb and some cli parquet tools but not too great.
CatQuest: that's monkey's mockup, all 👍 should go to him!
CatQuest
(I agree cb layout ha always been a tad odd)
... you whre th reporter so i was confused :D
alastairp
CatQuest: the only large con that we know of is what lucifer and I were just discussing - the data format is no longer text, so you need a 3rd party software library to read it
CatQuest
!m mofor mockups then!
BrainzBot
You're doing good work, mofor mockups then!!
CatQuest
...
!m monkey for mockups then!
BrainzBot
You're doing good work, monkey for mockups then!!
alastairp
I suspect that CB was much like every other project - a programmer makes a start and needs to lay out the data so comes up with something, but we never get around to looking at it from a design perspective
CatQuest
alastairp: yea.i was kinda joknig a little with Pratha-Fish, becasue they said "pros:" and didn't list cons :)
alastairp
there really are very few cons compared to the pros, though
now that we have the right people on board for design help, definitely agree that we should work to improve it
CatQuest
I dunno about design. but usability fro man user perspective
alastairp
sure, to me that's part of design too
CatQuest
i trust monkey explisitly, as he seems to also take that int oaccount, isntead of trying to be "fancy" for the sake of "design" or the sake of "just being fancy"
as i've seen other such people do :D
btw, have you seen the new entity editor that Shubh is xooking up for bb?
so far I've given feedback about performances (ostensibly on old browsers) but other's input re usability/design/ui/whatever would als obe usefull to them i think
skelly37 joined the channel
ROpdebee has quit
ROpdebee joined the channel
lucifer
monkey: alastairp: mayhem: we didn't have a LB meeting this month (last too). thoughts on doing one soon?
alastairp
yeah, let's do it. next week I'm away Mon-Weds
lucifer
i see, maybe later today or tomorrow if it works for all?
alastairp
tomorrow midday/early afternoon would be OK for me
d4rk-ph0enix has quit
d4rkie joined the channel
d4rkie has quit
mayhem
oh yes, sorry about that one.
tomorrow afternoon is pretty bad for me.
lucifer
next thursday/friday or maybe the monday of july 18 1 hr before regular meeting?
{kind=link}
{kind=link}
{kind=link}
{kind=link}