Ooh that is really nice though. Great use of the whole screen
I would like the opportunity to feed back on the details at some point if possible. Overall the usability looks great, how I would use it anyway. Some details could be workshopped a bit
Non-design feedback: As a user what would make this perfect is if I can go back and forth in time, and also filter by tags
I'm sure that will be easy 😁
mayhem
mooin!
aerozol: yes, back and forth in time is exactly the idea!
lucifer
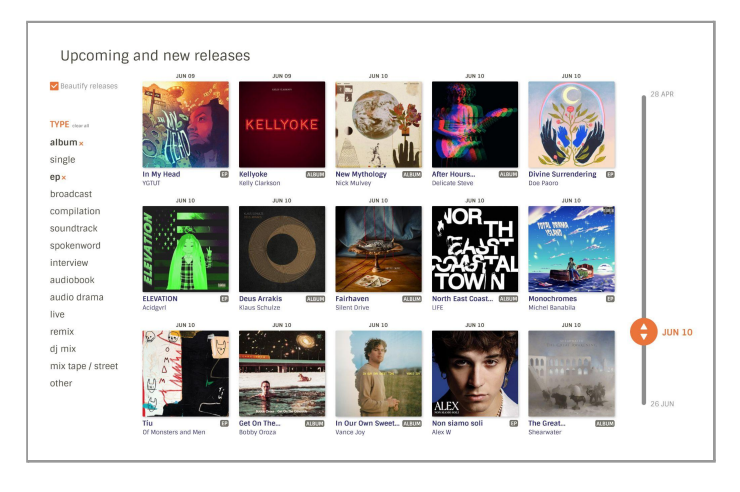
monkey: hi! when you have some time, can you please look into how we could make something like the slider in the mockup above?
lucifer: the branch spotify-release-index has the first attempt at the inverted index. except it takes hours to run the query -- my machine fell asleep before it completed after 4 or 5 hours or so.
if you feel like taking a look at my query to see if I am screwing it up, please take a look. in mbid_mapping/mapping/spotify_metata_index.py
lucifer
i cannot see the branch on github yet, is it pushed?
mayhem
otherwise I'll get back on it later next week.
sorry, fixed.
lucifer
thanks, will look into it. to confirm the index did build but took a long time?
mayhem
it never finished.
lucifer
ah ok
mayhem
on gaga there is a subset tmp_sp_metadata table that it does complete on.
sorry, rushing off to a conference this morning. not fully present
lucifer
yes there now, thanks!
mayhem
first conference in... how long?
I wonder how long before I walk out in disgust.
lucifer
hehe lol
ansh
lucifer: I found that every-time we create a new draft review, or we update the draft review, the avg_ratings table gets updated. This shouldn't be done. So I've fixed that also. So after this PR is merged, we need to run 2 queries in our main database. 1. To delete older draft revisions. 2. To delete the avg_ratings for the draft reviews.
alastairp
morning
lucifer
ansh: i see, makes sense. please add a comment on the PR so that we don't forget about this later.
alastairp
ansh: good catch, so we should only update it when something is published or edited?
ansh
yes
So whenever a draft review is published, the ratings get updated
Pratha-Fish
alastairp: Hi there
alastairp
hi Pratha-Fish, how are you?
Pratha-Fish
I'm doing fine, just got sidetracked for a few days due to personal issues.
I am back on track now tho
Working on the cleanup script RN
alastairp
ok great
do you have a draft version of it online that we can look at?
Pratha-Fish
I've not committed any changes yet, but I can do it RN
alastairp
yes please
Pratha-Fish
Currently I am writing it all in a jupyter notebook, but the structure of the script is there
alastairp: I've pushed the changes on the repo. Please refer to the notebook named "test_clean_master.ipynb"
CatQuest
hi Pratha-Fish !
🐟
Pratha-Fish
CatQuest: Hi!🐟
mayhem
Zas, alastairp , monkey, Freso : invoices plz
lucifer
mayhem: the query is sane. just too much data and turning jsonb into columns on the fly. asked on pg channel as well, solution ranges from using a materialized view which can improve speed by not bringing data from pg to python. but the query will still remain slow iiuc, we'll probably need to normalize the data to some extent to make this performant.
mayhem
Yeah, given that we need to rerun the query at least on a weekly basis, yes we need to.
Would making the key jsonb columns into real columns help this?
Or maybe we need to create artist/album/track tables for easier querying
Mineo joined the channel
skelly37 has quit
Pratha-Fish
alastairp: Is there a table that I can query using recording_MBID that gives an artist_credit_list as well as release_MBID?
alastairp
Pratha-Fish: that sounds like the previous query that we had to get the artist mbids
Pratha-Fish
alastairp: yes, but apparently I lost the query somewhere 🥲
alastairp
the `recording.artist_credit` field maps to `artist_credit.id` then `artist_credit_name.artist_credit` links to `artist_credit.id` and `artist_credit_name.artist` links to `artist.id` (from where you can get the `artist.gid`)
Pratha-Fish
I tried exploring existing queries, but none of them yielded the expected results
alastairp
give it a go to write a query, and let me know if you have any troubles
Pratha-Fish
sure. I am learning DBMS this semester as well. Shouldn't be too hard
lucifer
mayhem: yeah, i think a track level table would be a good start.
alastairp
Pratha-Fish: for release mbid, you can use `mapping.canonical_musicbrainz_data.recording_mbid`
on ac.id=artist_credit;``` seems to be working except for the release MBID part
lucifer
i'll look into how spotify treats mutliple releases of an album to see if it makes sense.
alastairp
Pratha-Fish: yes, right. however note that `ac.gid` is the mbid of the _artist credit_, not the mbids of the artists that make up that artist credit
Pratha-Fish
alastairp: right. I noticed that too. Looks like mapping.canonical_musicbrainz_data is the best bet here
lucifer
note that that table only has canonical recordings data not all recordings.
Pratha-Fish
lucifer: I was about to ask that same question lol
mayhem
lucifer: ordering by album_id to ensure that albums are processed in order
Pratha-Fish
Also, should it be a problem, considering that we'll be fetching canonical rec mbids for all possible recordings anyway?
lucifer
mayhem: oh duh, right. makes sense. i forgot to look at the python code.
alastairp
Pratha-Fish: ah right, canonical_musicbrainz_data also has a list of artist_mbids, perfect
Pratha-Fish
alastairp: But as lucifer pointed out, it only has canonical MBIDs. We'll be cleaning every rec_mbid to find its canonical_mbid anyway, but in case there's recording_MBIDs that work just fine, but for some reason don't have a canonical_MBID, we could be restricting the data too much.
monkey
chinmay: (cc lucifer) For the slider on the right of the fresh release page, we could very simply use an HTML slider and customize it with CSS. It's going to be the easiest and lightest method: https://blog.hubspot.com/website/html-slider
alastairp
lucifer: isn't an mbid which only has 1 recording the canonical mbid of itself?
lucifer
alastairp: yes. and there's two ways to check canonical recordings in our tables. 1) exists in canonical_musicbrainz_data 2) does not exist in canonical_recording_redirect table.
alastairp
there are 27.8m recordings, 21.5m canonical_musicbrainz_datas and 5.9m recording redirects
that pretty much adds up to the same number (modulo a bit of rounding)
lucifer
monkey: oh duh, makes sense, thanks.
alastairp: yes, give or take 100k for standalone recordings;
alastairp
lucifer: so I expect then that every recording in MB should have an entry in canonical_musicbrainz_data?
lucifer
alastairp: you mean after redirecting?
alastairp
if it's in musicbrainz_data, and isn't in recording_redirect, then that's fine. that's still the metadata for that recording mbid
monkey
There's some subtlety as to what action we take when the user changes the input (in particular we probably want a good debounce function to reduce the number of times we update the page) but it's all fairly easily figureoutable
alastairp
lucifer: no, not after redirecting. I mean for items which don't have a redirect
monkey
Do we have the enitre list of fresh releases when we load the page?
lucifer
alastairp: ah ok, yes.
monkey: yes.
monkey
OK, even easier then
We can use the percentage value from the slider to display the right slice of results.
alastairp
Pratha-Fish: it looks like it's fine, you should have all of the required metadata in that table
Pratha-Fish
alastairp: Great!
And eitherway, we'll be finding redirects and canonical IDs for all IDs, so we can check the few remaining outliers manually to see what we're missing
mayhem
First mention of Blockchain and NFTs. Sigh
lucifer
alastairp: 2 catches which probably don't matter but fyi, 1) standalone recordings - no canonical table has that but those are a small proportion anyway. 2) there will always be some canonical recording data in canonical_musicbrainz_data for every canonical mbid but the canonical mbids in themselves are not stable across runs. generating that twice will probably yield different results each time.
mayhem
Huh. 70% of bandcamp users are looking for new music. A stark contrast to the rest industry.
monkey
Indeed
alastairp
lucifer: I think we found that the proportion of standalone recordings in mlhd was small enough that we can probably ignore them for this? I think it'll be fine
lucifer: the non-stable across runs is because we might have 2 things with all the same fields, and so there is no explicit order?
lucifer
yes to both.
alastairp
I think that's OK - perhaps if possible we should add a tie breaker on recording.gid or recording.id anyway to make it stable, but perhaps not a huge issue either
lucifer
the difference is in medium or track number which our ordering does not consider.
makes sense
alastairp
just some thinking out loud - I think it makes sense that if we declare something as "canonical", then over multiple runs that should stay stable. I don't mind if something becomes "more canonical" based on more data being added to the mb database, that's kinda normal
agatzk has quit
agatzk joined the channel
atj
mayhem: 99% sure the address on the wiki for AirBNB #1 is incorrect and the address on the booking page is correct.
one of the reviews mentions that a restaurant called Xines Nord is across the street, which tallies with the address on the booking page.
mayhem
Yes, that is finally clear. Please update the wiki.
ansh: i can look into it in some time but on a very quick scan you probably want at least one of the histograms in do update to be excluded.histogram
remeber that the new data will be in excluded.histogram and old one in just histogram.
ansh
Oh understood. But i am getting this error in line 11 of this paste. "VALUES ('42ca4d72-41cd-4874-aedf-8ff6bb2c18d2', 'release_group', 80, 1, jsonb_set(histogram, '1' , (COALESCE(histogram->>'2','0')::int + 1)::text::jsonb))"
ah right. you cannot use the columns of a table in values clause like that.
ansh
I think it is because since I am adding a new row, there is no previous value to update, so therefore the error .
lucifer
just always insert a new histogram in values and let do update handle the case of existing rows
ansh
okay, I'll try that
lucifer
if you really need the old row in values, we can use a cte to get that row before insert but so far i dont think ot should be needed.
ansh
Can we set the value for this column from the default value `{"1" : 0, "2" : 0, "3" : 0, "4" : 0, "5" : 0}` to `{"1" : 0, "2" : 1, "3" : 0, "4" : 0, "5" : 0}`?
while adding a new row without conflict ?
lucifer
sure instead of using histogram in values, hardcode the default.
ansh
No I mean, I have set the default to `{"1" : 0, "2" : 0, "3" : 0, "4" : 0, "5" : 0}`. Now whenever I add a new row, I can just update `2` to 1 ?
* the value of key "2" to 1
lucifer
ansh: iiuc you set this as the default value for the column in create table. in that case not sure but probably no cant do that. however you can directly put this value in jsonb_set call and that should work.
alastairp: I checked out what would happen if we straightup replace all artist_MBIDs and release_MBIDs from MLHD with the ones we fetch based upon cleaned recording_MBIDs. Here's the results:
% Coverage of recording MBIDs: w/ MLHD: 0.87
% Coverage of recording MBIDs: w/ cleaned recording_MBID: 0.97
% Coverage of release MBIDs: w/ MLHD: 0.87
% Coverage of release MBIDs: w/ cleaned recording_MBID: 0.79
{kind=link}
{kind=link}