yeah makes, its now just adding a handler in initial conf and be done with it.
2021-04-27 11758, 2021
_lucifer
*makes sense
2021-04-27 11741, 2021
leroivi has quit
2021-04-27 11750, 2021
_lucifer
i was thinking to remove pytest deps from reuirements_spark.txt by add another step to build test image in Dockerfile.spark.thoughts?
2021-04-27 11726, 2021
alastairp
yeah, no problem. though can we reuse requirements_dev to install them?
2021-04-27 11712, 2021
_lucifer
no actually we have them in requirements_spark.txt as well.
2021-04-27 11721, 2021
_lucifer
ah yes right we can
2021-04-27 11736, 2021
MRiddickW joined the channel
2021-04-27 11727, 2021
alastairp
yeah, great. I just didn't want to hard-code dependencies in Dockerfile, and I didn't want _another_ requirements file
2021-04-27 11756, 2021
mckean has quit
2021-04-27 11724, 2021
mckean joined the channel
2021-04-27 11726, 2021
reosarevok
yvanzo: around?
2021-04-27 11734, 2021
_lucifer
alastairp: what do you think we should do about pyspark dep? adding to requirements_development.txt seems wrong. if we keep in requirements_spark.txt it'll be for sake of tests only.
2021-04-27 11753, 2021
alastairp
ah, interesting question
2021-04-27 11704, 2021
_lucifer
also, i saw you added `sentry_sdk[pyspark]` instead of just `sentry_sdk` any particular reason?
2021-04-27 11724, 2021
alastairp
I think it makes sense to keep it in requirements_spark.txt, it feels like the better place for it
2021-04-27 11752, 2021
alastairp
mmm, good point. sentry_sdk[pyspark] ensures that pyspark is also installed (it makes it a dependency)
2021-04-27 11729, 2021
_lucifer
i don't think we want that as pyspark should be provided externally by spark
2021-04-27 11737, 2021
_lucifer
and we uninstall it just after anyways
2021-04-27 11753, 2021
alastairp
but if the spark setup provides pyspark without us needing to add it, perhaps just sentry_sdk is OK
2021-04-27 11703, 2021
alastairp
why do we uninstall it?
2021-04-27 11719, 2021
alastairp
I don't know how the spark/pyspark thing works
2021-04-27 11739, 2021
alastairp
how does spark provide pyspark? does it put it in sys.path? is it before or after the rest of our dependencies?
2021-04-27 11739, 2021
_lucifer
because we pack the deps in venv in a zip and send it to all spark workers
2021-04-27 11740, 2021
yvanzo
reosarevok: yup
2021-04-27 11756, 2021
reosarevok
yvanzo: see my comments on the PR :)
2021-04-27 11744, 2021
_lucifer
i am not familiar with how it works under the hood to supply pyspark.
2021-04-27 11731, 2021
alastairp
neither am I
2021-04-27 11747, 2021
alastairp
sorry, I don't have a lot of time today. I'll be at the office tomorrow and would be happy to talk through it with you
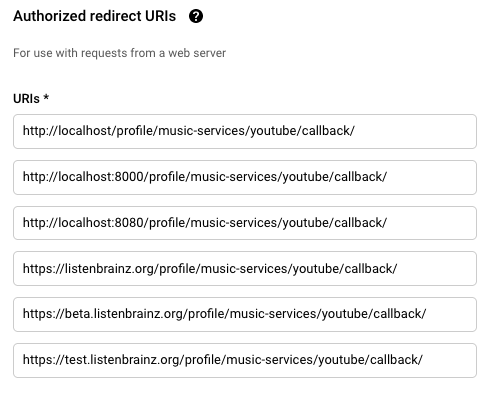
we'll need to add some redirect uris for spotify as well to test on beta. but not needed urgently that can be done tomorrow.
2021-04-27 11710, 2021
kyledecot joined the channel
2021-04-27 11744, 2021
kyledecot
Cross-posting this from #musicbrainz
2021-04-27 11744, 2021
kyledecot
Hello everyone! I'm building a website that will allow guitarists to upload Guitar Pro files–as part of this I want to use MusicBrainz to lookup additional metadata about the artist such as their canonical name, aliases, genres, etc. I've looked over the schema for the DB but I'm still a bit unsure how to traverse it to get the information I
2021-04-27 11745, 2021
kyledecot
want. My thinking was that I would search for the "Work" by name and then get to the Artist from that. Using "Toxicity" as an example however you can see that the relationships do not include "System of a Down" https://beta.musicbrainz.org/work/ab2a78d4-b0ce-3… It looks as though I would have to inspect the recordings
2021-04-27 11745, 2021
kyledecot
to somehow derive the "canonical" recording/artist but I'm unsure if my assumptions are correct or if there is another way to go about this. Any help in regards to this would be greatly appreciated!
2021-04-27 11709, 2021
ruaok
_lucifer: syswiki updated.
2021-04-27 11720, 2021
_lucifer
thanks!
2021-04-27 11726, 2021
ruaok
reosarevok: can you please help kyledecot?
2021-04-27 11720, 2021
_lucifer
Mr_Monkey: in the mockups I see we do not show import details there. that's expected.
2021-04-27 11737, 2021
_lucifer
s/expected/intended?
2021-04-27 11736, 2021
nelgin
How can I determine if live indexing is turned on with the musicbrainz vm?
I got the MBID matcher running live against incoming listens:
2021-04-27 11743, 2021
ruaok
listens: exact 1785 high 20 med 154 low 55 no 873 err 0
2021-04-27 11748, 2021
ruaok
68% match rate. :)
2021-04-27 11700, 2021
ruaok
no trouble keeping up with incoming listens.
2021-04-27 11702, 2021
reosarevok
kyledecot: hi! Give me a moment if that's ok? I'm making dinner :)
2021-04-27 11714, 2021
ruaok
on thursday I'll add support for working through old listens.
2021-04-27 11738, 2021
nelgin
Well, my system spent from 2:17am to 4:06pm UTC loading the indexes and it's still not finding any results.
2021-04-27 11755, 2021
reosarevok
kyledecot: oh, I see you're getting help in #musicbrainz, will check for a mo
2021-04-27 11701, 2021
reosarevok
yvanzo: can you help nelgin ?
2021-04-27 11733, 2021
reosarevok
kyledecot: oh, no, I'm being dumb. Sorry. Ok, I'll quickly look, food is in the oven anyway
2021-04-27 11734, 2021
reosarevok
So
2021-04-27 11758, 2021
reosarevok
Yes, you can't trivially get from the work to a "canonical artist", because we don't really have those
2021-04-27 11733, 2021
reosarevok
(for example, many works don't really have those, such as classical, folk and even some jazz music)
2021-04-27 11719, 2021
reosarevok
For what you want, the most common case is going to be "find a recording, and pick the artist". But do you have any artist name to begin with?
2021-04-27 11744, 2021
reosarevok
Because if all you have is, say, the word "Dumb", there's no good way to know if you should be picking Nirvana or Garbage (or someone else)
2021-04-27 11752, 2021
kyledecot
reosarevok Yeah I have the artist name to begin with (it's encoded into the Guitar Pro file). I thought I should start at the "work" to also get the canonical title (in case they submit something like "toXiciTY" or something.
2021-04-27 11719, 2021
reosarevok
Well, the problem is sometimes we won't even have works, especially for popular music
2021-04-27 11743, 2021
reosarevok
Those are not added automatically, they're added by users mostly when they need to either link covers or add a composer / lyricist
Oh I see–so would it be safer to just try and look up the artist directly and then attempt to get the work separately (basically split this into two problems)?
2021-04-27 11751, 2021
reosarevok
I would suggest trying to find a recording using title + artist
2021-04-27 11707, 2021
reosarevok
And then you can check whether the recording is linked to any works if you want info from them :)
2021-04-27 11702, 2021
reosarevok
(if it is, you could use the work title as the standard title, while if not, you could just default to the recording title, which might already be an improvement - for example, a search for toXiciTY would probably give you a recording named Toxicity anyway :) )
2021-04-27 11736, 2021
nelgin
I rebooted my vm and restarted the docker and now it appears to be working.
2021-04-27 11730, 2021
kyledecot
reosarevok that all makes sense–my main blocker was just knowing which resource / entity to start with. I'll probably have additional questions as I continue to develop this but you've done a great job in giving me a direction to head in. Thanks for the quick response / building such an awesome / open platform!
2021-04-27 11740, 2021
reosarevok
kyledecot: neat! Don't hesitate to come back and ask more
2021-04-27 11754, 2021
Mr_Monkey
_lucifer: missing import details is not intended, no. We'll have to find some space for it
2021-04-27 11719, 2021
_lucifer
Mr_Monkey: should we put it on another page?
2021-04-27 11716, 2021
Mr_Monkey
I think it makes sense to keep it with each music service in that page. Maybe an "Import details" accordion hidden by default?
2021-04-27 11730, 2021
_lucifer
yeah that could work
2021-04-27 11735, 2021
yvanzo
nelgin: Solr works asynchronously. It takes extra time for search indexes to be readily available.
2021-04-27 11749, 2021
yvanzo
I’m working on improving stuff around BASE_FTP_URL variable you mentioned yesterday.
2021-04-27 11747, 2021
yvanzo
When live indexing is working, reindex messages are queued. So you can check either logs of 'mq' or 'search' services.
2021-04-27 11705, 2021
kyledecot has quit
2021-04-27 11709, 2021
yvanzo
'indexer' logs can also be useful: it indicates when reindex messages are processed with timestamp.
indexer_1 | 2021-04-27T16:24:57.994325142Z 2021-04-27 16:24:57,993: Error encountered while processing messages: Post to Solr failed. Requeueing all pending messages for retry.
2021-04-27 11742, 2021
nelgin
I'm going to pastebin this entire log - tehre's all sorts of stuff in here.
2021-04-27 11751, 2021
yvanzo
Please pastebin the ouput of this command too: sudo docker-compose exec mq rabbitmqadmin -u sir -p sir -V /search-index-rebuilder list queues
{kind=link}