solr-cloud-1 was rebooted half an hour ago, someone did this ?
2018-07-10 19146, 2018
zas
7:12:16 utc
2018-07-10 19159, 2018
zas
samj1912 ^^
2018-07-10 19144, 2018
samj1912
Nope
2018-07-10 19150, 2018
samj1912
Afk for a while now
2018-07-10 19135, 2018
loujine has quit
2018-07-10 19136, 2018
HSOWA has quit
2018-07-10 19140, 2018
ruaok
yvanzo_: the VM ballooned to 20GB this time around.
2018-07-10 19150, 2018
ruaok
also MOOOIN! \ø-
2018-07-10 19134, 2018
ruaok
latest MV is now available on the FTP site, md5 generating.
2018-07-10 19100, 2018
loujine joined the channel
2018-07-10 19141, 2018
zas
Moooin ruaok
2018-07-10 19124, 2018
zas
solr-1 rebooted "alone" at 7:12:16 UTC, after being unavailable for ~30 mins, i have no explanation for now
2018-07-10 19151, 2018
ruaok
I didn't do it.
2018-07-10 19156, 2018
zas
i suspect underlying hardware issue, but i see nothing in Hetzner status
2018-07-10 19116, 2018
ruaok
is it just me or does it seem that hetzner's cloud isn't nearly as stable as AWS or GC?
2018-07-10 19130, 2018
ruaok
probably built on the same crap consumer hardware is my guess.
2018-07-10 19134, 2018
zas
it isn't just you ;)
2018-07-10 19144, 2018
zas
prices... are quite different
2018-07-10 19109, 2018
ruaok
I'm thinking of writing them an actual letter. not just a tech support message. but an actual letter that says that their shit sucks.
2018-07-10 19154, 2018
ruaok
because as with their other offerings, we're putting in a lot of effort to keep things running when we shouldn't have to.
2018-07-10 19106, 2018
zas
well, their cloud is quite new, and we know their weaknesses, for me that's a non-issue, if we are able to make our systems fault-tolerant enough
2018-07-10 19149, 2018
zas
after, that's a question of money: human-time has a cost
2018-07-10 19155, 2018
ruaok
yeah, a good excercise for us. still, we're wasting time on it.
2018-07-10 19105, 2018
ruaok
exactly.
2018-07-10 19153, 2018
zas
i don't see that as a real waste of time, unreliable underlying hardware force us to improve the fault-tolerance of our systems, which is imho very good
2018-07-10 19139, 2018
zas
current solr stuff can easily lost a node (but not 2), at worse we can spawn a new one and configure it under 30 mins
2018-07-10 19121, 2018
zas
reliable hardware leads to non-fault-tolerant systems, and when something bad happens .... that's catastrophic ;)
2018-07-10 19136, 2018
ruaok
agreed.
2018-07-10 19158, 2018
ruaok
but once we remove all single points of failure, if we still need to play this stupid game, then we're wasting efforts.
2018-07-10 19123, 2018
zas
once we'll remove all single points of failure, we'll not care failures anymore ;)
2018-07-10 19158, 2018
zas
but we still have too many atm
2018-07-10 19158, 2018
zas
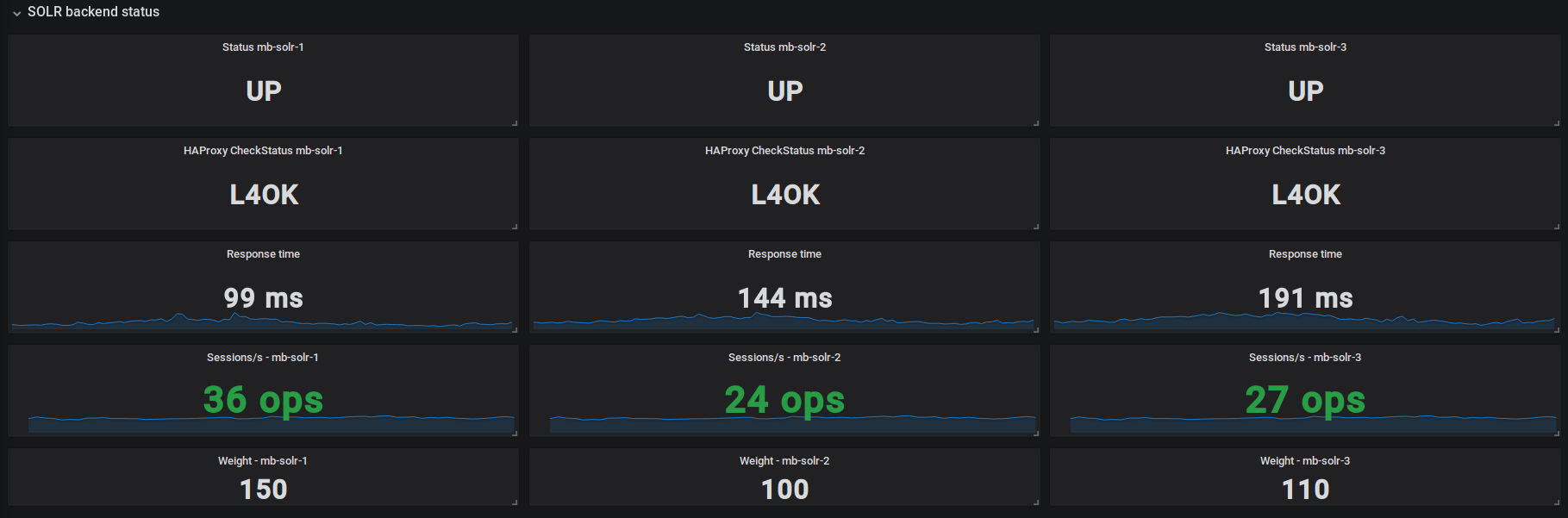
the main problem for me with hetzner cloud is that cpu resources "actually available" aren't really predictable, and i have the feeling they stole us in this regard
2018-07-10 19123, 2018
zas
difference between all SOLR nodes is quite significative
2018-07-10 19131, 2018
ruaok
yes.
2018-07-10 19104, 2018
ruaok
can you do me a favor and find one graph that clearly indicates that the performance between equal nodes is clearly different over a long period of time?
ruaok: For creating clusters using fetched release MBIDs, I compare release_name with fetched release names(multiple releases are there for single recording in most cases) and if I get a single match I associate that release MBID to the recording else nothing is associated. But in case we have only one release right now for some recording e.g. https://musicbrainz.org/release/485e33dd-d8f2-4ac…. Suppose we get recording like
2018-07-10 19148, 2018
kartikeyaSh
{"title":"Farewell to Ireland", "artist": "James Morrison", "release": "Irish Favourites", "recording_mbid":"https://musicbrainz.org/recording/13d6a027-3dae-4f4d-a08a-3ba044f7a257"}. So, do I associate release MBID https://musicbrainz.org/release/485e33dd-d8f2-4ac… to this recording or not? Maybe in future, some other release for this recording can be inserted into the MusicBrainz database. So, our association will become incorrect
2018-07-10 19149, 2018
kartikeyaSh
but for now, it's the only known release with the given name so the association is correct.
2018-07-10 19134, 2018
Nyanko-sensei has quit
2018-07-10 19147, 2018
UmkaDK
Guys, a quick schema upgrade question: will there be one in October?
2018-07-10 19109, 2018
D4RK-PH0ENiX joined the channel
2018-07-10 19159, 2018
ruaok
UmkaDK: unlikely. we haven't decided yet, but there have been no real musings that I've caught.
2018-07-10 19122, 2018
ruaok
I' m really more in favor of getting some single points of failure and UX things moving.
2018-07-10 19149, 2018
UmkaDK
Thanks ruaok!
2018-07-10 19154, 2018
ruaok
kartikeyaSh: gimme a few minutes to go to the office and then you're on top of my todo list.
{kind=link}