-
kuno joined the channel
-
Freso__ joined the channel
-
lucifer_ joined the channel
-
Freso__ is now known as Freso
-
lucifer has quit
-
lucifer_ is now known as lucifer
-
yyoung joined the channel
-
leonardo has quit
-
leonardo joined the channel
-
antlarr_away has quit
-
antlarr joined the channel
-
yyoung
-
thomasross has quit
-
akashgp0971 joined the channel
-
akashgp09_ joined the channel
-
akashgp0971 has quit
-
bitmap
-
yyoung
-
bitmap
-
akashgp09_ has quit
-
akashgp09_ joined the channel
-
akashgp09_ has quit
-
akashgp09_ joined the channel
-
akashgp09_ is now known as akashgp09
-
akashgp09 has quit
-
akashgp09_ joined the channel
-
akashgp0973 joined the channel
-
akashgp0973 has left the channel
-
BrainzGit
-
lucifer
-
lucifer
-
lucifer
-
shivam-kapila
-
lucifer
-
monkey has quit
-
outsidecontext_ joined the channel
-
outsidecontext_ has quit
-
outsidecontext_ joined the channel
-
monkey joined the channel
-
agatzk has quit
-
agatzk joined the channel
-
monkey has quit
-
ruaok
-
outsidecontext has quit
-
monkey joined the channel
-
ruaok
-
outsidecontext joined the channel
-
ruaok
-
outsidecontext_ has quit
-
outsidecontext_ joined the channel
-
outsidecontext_ has quit
-
outsidecontext_ joined the channel
-
outsidecontext has quit
-
flamingspinach has quit
-
param has quit
-
slush has quit
-
outsidecontext joined the channel
-
outsidecontext_ has quit
-
param joined the channel
-
slush joined the channel
-
lucifer
-
lucifer
-
ruaok
-
ruaok
-
lucifer
-
lucifer
-
ruaok
-
ruaok
-
ruaok
-
lucifer
-
lucifer
-
lucifer
-
ruaok
-
ruaok
-
lucifer
-
ruaok
-
ruaok
-
lucifer
-
ruaok
-
monkey
-
ruaok
-
monkey
-
monkey
-
lucifer
-
lucifer
-
monkey
-
monkey
-
monkey
-
lucifer
-
monkey
-
monkey
-
lucifer
-
monkey
-
monkey
-
lucifer
-
monkey
-
monkey
-
lucifer
-
monkey
-
lucifer
-
lucifer
-
monkey
-
lucifer
-
lucifer
-
lucifer
-
lucifer
-
monkey
-
monkey
-
lucifer
-
monkey
-
monkey
-
monkey
-
lucifer
-
monkey
-
monkey
-
monkey
-
monkey
-
lucifer
-
monkey
-
monkey
-
lucifer
-
monkey
-
lucifer
-
monkey
-
monkey
-
monkey
-
monkey
-
BrainzGit
-
lucifer
-
BrainzGit
-
BrainzGit
-
lucifer
-
monkey
-
lucifer
-
monkey
-
lucifer
-
atj
-
atj
-
monkey
-
lucifer
-
monkey
-
shivam-kapila
-
atj
-
BrainzGit
-
monkey
-
atj
-
atj
-
BrainzGit
-
Rotab
-
atj
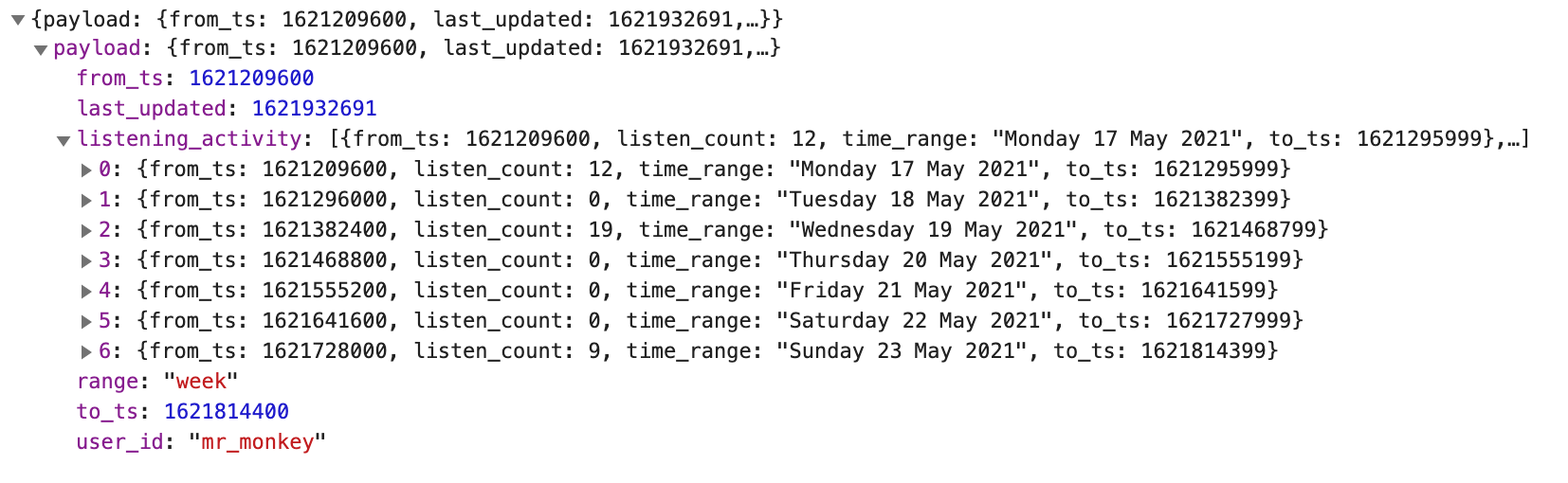{kind=link}
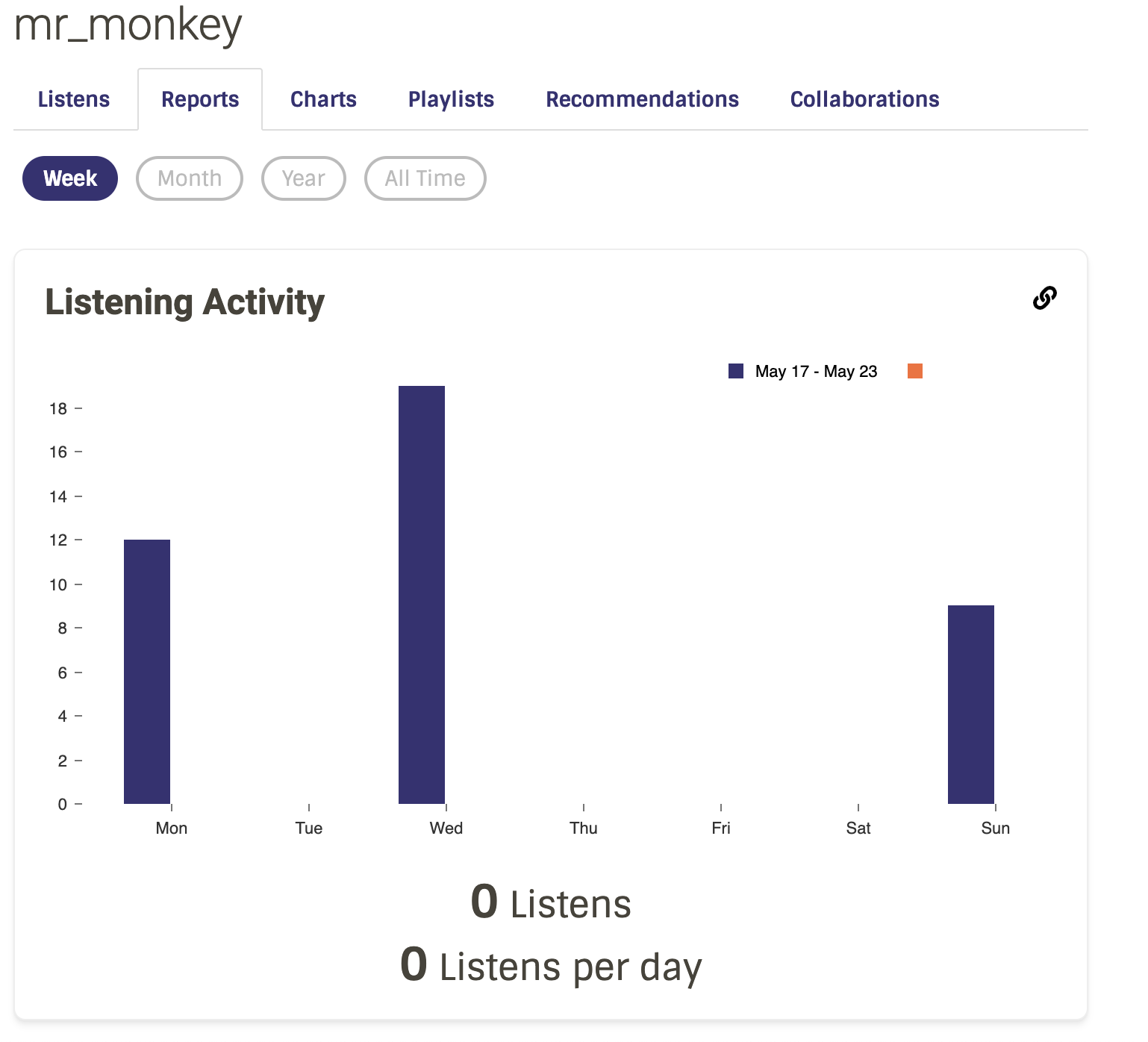{kind=link}
{kind=link}