-
d4rkie joined the channel
-
d4rk-ph0enix has quit
-
santiagofn joined the channel
-
MRiddickW joined the channel
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
darkstardevx joined the channel
-
monotux has quit
-
monotux joined the channel
-
BrainzGit
-
aerozol
-
BrainzGit
-
d4rkie has quit
-
d4rkie joined the channel
-
d4rkie has quit
-
MRiddickW has quit
-
d4rkie joined the channel
-
reosarevok
-
reosarevok
-
d4rkie has quit
-
d4rkie joined the channel
-
bitmap
-
reosarevok
-
reosarevok
-
reosarevok
-
reosarevok
-
bitmap
-
bitmap
-
reosarevok
-
reosarevok
-
reosarevok
-
bitmap
-
reosarevok
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
bitmap
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
Pratha-Fish
-
reosarevok
-
reosarevok
-
BrainzGit
-
antlarr has quit
-
antlarr joined the channel
-
d4rk-ph0enix joined the channel
-
d4rkie has quit
-
alastairp
-
alastairp
-
alastairp
-
alastairp
-
alastairp
-
alastairp
-
antlarr has quit
-
KassOtsimine has quit
-
reosarevok has quit
-
zas has quit
-
mruszczyk has quit
-
reosarevok joined the channel
-
KassOtsimine joined the channel
-
zas joined the channel
-
mruszczyk joined the channel
-
milkii has quit
-
alastairp
-
BrainzBot
-
BrainzBot
-
milkii joined the channel
-
lucifer
-
alastairp
-
antlarr joined the channel
-
alastairp
-
alastairp
-
lucifer
-
lucifer
-
alastairp
-
alastairp
-
alastairp
-
lucifer
-
lucifer
-
alastairp
-
lucifer
-
alastairp
-
lucifer
-
lucifer
-
alastairp
-
lucifer
-
lucifer
-
alastairp
-
alastairp
-
alastairp
-
lucifer
-
alastairp
-
MRiddickW joined the channel
-
alastairp
-
alastairp
-
Lotheric_ joined the channel
-
Lotheric has quit
-
CatQuest
-
CatQuest
-
CatQuest
-
BrainzBot
-
alastairp
-
CatQuest
-
CatQuest
-
alastairp
-
CatQuest
-
BrainzBot
-
CatQuest
-
CatQuest
-
BrainzBot
-
alastairp
-
CatQuest
-
alastairp
-
alastairp
-
CatQuest
-
alastairp
-
CatQuest
-
CatQuest
-
CatQuest
-
CatQuest
-
CatQuest
-
CatQuest
-
skelly37 joined the channel
-
ROpdebee has quit
-
ROpdebee joined the channel
-
lucifer
-
alastairp
-
lucifer
-
alastairp
-
d4rk-ph0enix has quit
-
d4rkie joined the channel
-
d4rkie has quit
-
mayhem
-
mayhem
-
lucifer
-
zas
-
mayhem
-
d4rkie joined the channel
-
d4rkie has quit
-
d4rkie joined the channel
-
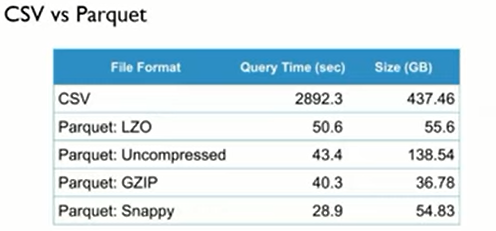
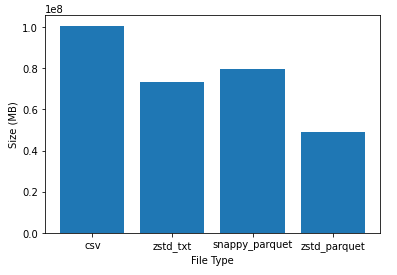
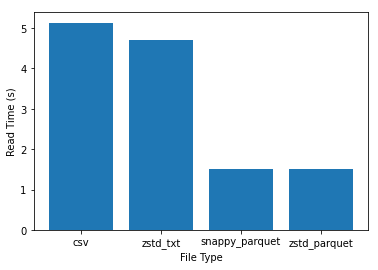
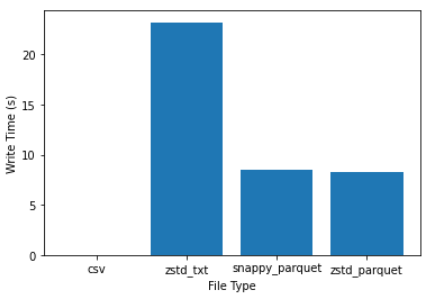
ansh
{kind=link}
{kind=link}
{kind=link}
{kind=link}