almost all the elements are ready to be assembled. It's in a jupyter notebook right now for testing, etc
2022-07-14 19502, 2022
Pratha-Fish
Ah I see
2022-07-14 19503, 2022
Pratha-Fish
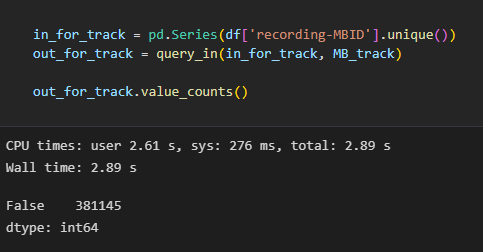
This code isn't working with unique MBIDs!
2022-07-14 19507, 2022
zas
skelly37, outsidecontext : hey, what about usual meeting time?
2022-07-14 19530, 2022
outsidecontext
ok, works for me
2022-07-14 19541, 2022
alastairp
Pratha-Fish: hm, right. but you're right that this still seems to be much longer than I'd expect
2022-07-14 19557, 2022
Pratha-Fish
That's right
2022-07-14 19506, 2022
Pratha-Fish
Thankfully I've just realized a few optimizations here
2022-07-14 19530, 2022
Pratha-Fish
i.e. Taking only unique rows
2022-07-14 19531, 2022
skelly37
Fine for me
2022-07-14 19519, 2022
alastairp
I'm loading and running the code now to see if I can recommend something
2022-07-14 19528, 2022
Pratha-Fish
alastairp: The other faster optimization is just logging the "recording-MBID" that was marked as a track-MBID.
2022-07-14 19528, 2022
Pratha-Fish
It's more complicated under the hood than it sounds actually
2022-07-14 19532, 2022
Pratha-Fish
sure
2022-07-14 19526, 2022
zas
atj: I'd like we progress on ansible crowdsec stuff, what about deploying it on rex & rudi to experiment and improve?
2022-07-14 19522, 2022
alastairp
Pratha-Fish: just to check - `df_test_positive` is a sample dataframe that you created that includes some track ids and some track redirects, so that you can test the method?
2022-07-14 19556, 2022
Pratha-Fish
alastairp: yes that's right
2022-07-14 19500, 2022
alastairp
ok, great
2022-07-14 19558, 2022
alastairp
Pratha-Fish: it looks to me like this specific pandas operation is really inefficient and we should target it
2022-07-14 19510, 2022
Pratha-Fish
exactly
2022-07-14 19521, 2022
alastairp
the first thing that I'd think of in this case is to just use a basic loop + counter. take a look at this:
put it in 2 - converting the track gids to a set only has to be done once
2022-07-14 19511, 2022
Pratha-Fish
oh right
2022-07-14 19527, 2022
Pratha-Fish
This time, let's also try doing it on both MB_track and MB_track_redir
2022-07-14 19501, 2022
Pratha-Fish
All right, so plain python test is taking 11s for set conversion, and 300microseconds for the test!
2022-07-14 19511, 2022
alastairp
mmmhm
2022-07-14 19523, 2022
Pratha-Fish
* For both MB_track and MB_track_redir
2022-07-14 19540, 2022
alastairp
so, in one way I'm surprised that the "typical" way that you might do it in pandas is so slow
2022-07-14 19543, 2022
Pratha-Fish
It's probably due to the massive conversion overhead in pandas!
2022-07-14 19545, 2022
alastairp
but it's also important to work out what our goal is - we could generate the intersection of the 2 dataframes and save it, but we could also do this in 2 phases - 1) quickly look at all items and then if we see something, 2) save the filename for further analysis
2022-07-14 19502, 2022
alastairp
my guess is because both of these dataframes in pandas are lists
2022-07-14 19525, 2022
alastairp
try `track_mbid_list = MB_track.gid.tolist()` and use `if recid in track_mbid_list:` instead
2022-07-14 19525, 2022
Pratha-Fish
alastairp: Yes, that's exactly how I am logging the anomalies
2022-07-14 19525, 2022
Pratha-Fish
Only the suspected MBID, and it's file path
2022-07-14 19548, 2022
alastairp
and you'll see that this kind of check against a list is _way_ slower
2022-07-14 19517, 2022
Pratha-Fish
Python sets for the win!
2022-07-14 19539, 2022
alastairp
well, keep in mind that this is "datastructures for the win", using the correct tool for the job
2022-07-14 19556, 2022
alastairp
this is O-notation, if you've covered it before in classes
2022-07-14 19506, 2022
Pratha-Fish
Yes I am aware of it
2022-07-14 19527, 2022
Pratha-Fish
Now I see why DSA is so important in interviews
2022-07-14 19556, 2022
alastairp
I just tested `if recid in track_mbid_list:` on the 6 item dataset, and it took about 16 seconds
2022-07-14 19556, 2022
Pratha-Fish
Looks like py set datastructure is implemented on hashmaps. Probably the biggest reason for these ridiculous lookup speeds
2022-07-14 19510, 2022
alastairp
that's really close to the 20 that we saw with pandas
2022-07-14 19517, 2022
Pratha-Fish
right
2022-07-14 19527, 2022
Pratha-Fish
I also modified my pandas code a little, and it's taking ~14s now
2022-07-14 19557, 2022
alastairp
yes, right. when you have a list [1,2,3,4,5,6] and you want to check `if 8 in mylist` then it has to look at each item in the list. if it's not in the list you have to go through the entire list every single time you check
2022-07-14 19522, 2022
alastairp
whereas with a hashed datastructure like a set (python dictionary keys work the same way), its just a hash operation + 1 lookup
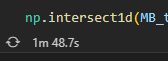
Let's try out the intersection method. It's written in numpy, so it's gotta be pretty fast for such a basic operation
2022-07-14 19558, 2022
alastairp
note that in that microbenchmark it's still faster to convert the series to a set, do the intersection, turn it back into a python list, and then turn that into a Series again (the first item, almost 10% faster than the last one)
2022-07-14 19516, 2022
alastairp
.intersection is a python set method
2022-07-14 19525, 2022
alastairp
.intersect1d is a numpy method
2022-07-14 19543, 2022
Pratha-Fish
right, so the method with set is still gonna be faster I assume
2022-07-14 19533, 2022
Pratha-Fish
Let's check out both of them just in case
2022-07-14 19544, 2022
alastairp
sure, it'd be good to take a look at them
2022-07-14 19502, 2022
alastairp
one other thing that I noticed - after you select the data from the database, they are a UUID object:
and it looks like this object has an "equality" method to compare other UUID objects and strings of UUIDs, but it looks like it's faster if we just treat them as strings
2022-07-14 19519, 2022
lucifer
mayhem: hi! by any chance, do we have extra MeB tshirts available at office? :)
2022-07-14 19503, 2022
Pratha-Fish
alastairp: yes, I noticed that one too.
2022-07-14 19503, 2022
Pratha-Fish
I also tried explicitly loading MLHD data with all UUID columns specified as string
2022-07-14 19503, 2022
Pratha-Fish
But somehow it gets converted into UUID along the way
ansh: I'll also take a look at your search PR again, and the other API ones you added (you need the metadata and rating one for BB integration, right?)
2022-07-14 19549, 2022
ansh
yes
2022-07-14 19553, 2022
ansh
It was really great reviewing a PR :) Thank you for this opportunity
{kind=link}
{kind=link}
{kind=link}