aerozol: huh, I hadn't heard anyone mention a scaling issue with the artist dialog yet, but I can see what you mean from your screenshot. you are on windows right? I can boot into windows and try to reproduce it later
also let me know what browser you're using
aerozol
Bitmap: yup windows + chrome, I'm not home at the moment but I can send versions later if needed
vibhoo_24 joined the channel
vibhoo_24 has quit
vibhoo_24 joined the channel
vibhoo_24 has quit
vibhoo_24 joined the channel
vibhoo_24 has quit
kidd_73 joined the channel
kidd_73 has quit
mayhem: the question is for a manual scrobbler - if someone is submitting a vinyl from MB, that doesn't have times on it, how should the plugin calculate timestamps
I guess we could just put a generic time like assume the song is 1:50 or something
lucifer: in these cases they usually wouldn't have the files I think, they'd be loading a release from the db into Picard. But they may have files
jivte joined the channel
jivte has quit
jivte joined the channel
vibhoo_24 joined the channel
jivte has quit
jivte joined the channel
vibhoo_24 has quit
vibhoo_24 joined the channel
jivte has quit
vibhoo_24 has quit
lucifer
mayhem: i checked your recent listens and didn't find Running up the Hill in last 10 days.
maybe an issue in submitting listens or something related?
schickling[m]: we have a tool called `mbid_mapping_writer` that assigns matches listens to recordings in MB. it has 2 ways to to this, an exact match of the aritst and track name. the second option is a matrix of fuzzy searches, detuned comes into play here detuned means that we modified the original track and artist name submitted by the user in the attempt to find a match.
vibhoo_24 joined the channel
vibhoo_24
lucifer: I have made a new folder with the name utils inside listenbrainz-server/listenbrainz_spark/hdfs and inside that made a file __init__.py and moved all the functions which were related to hdfs from that file to this file.Please correct me if I am wrong.
lucifer
vibhoo_24: you can open a PR with the changes. i'll try to review it soon. if something needs to be changed will let you know on the PR>
mayhem
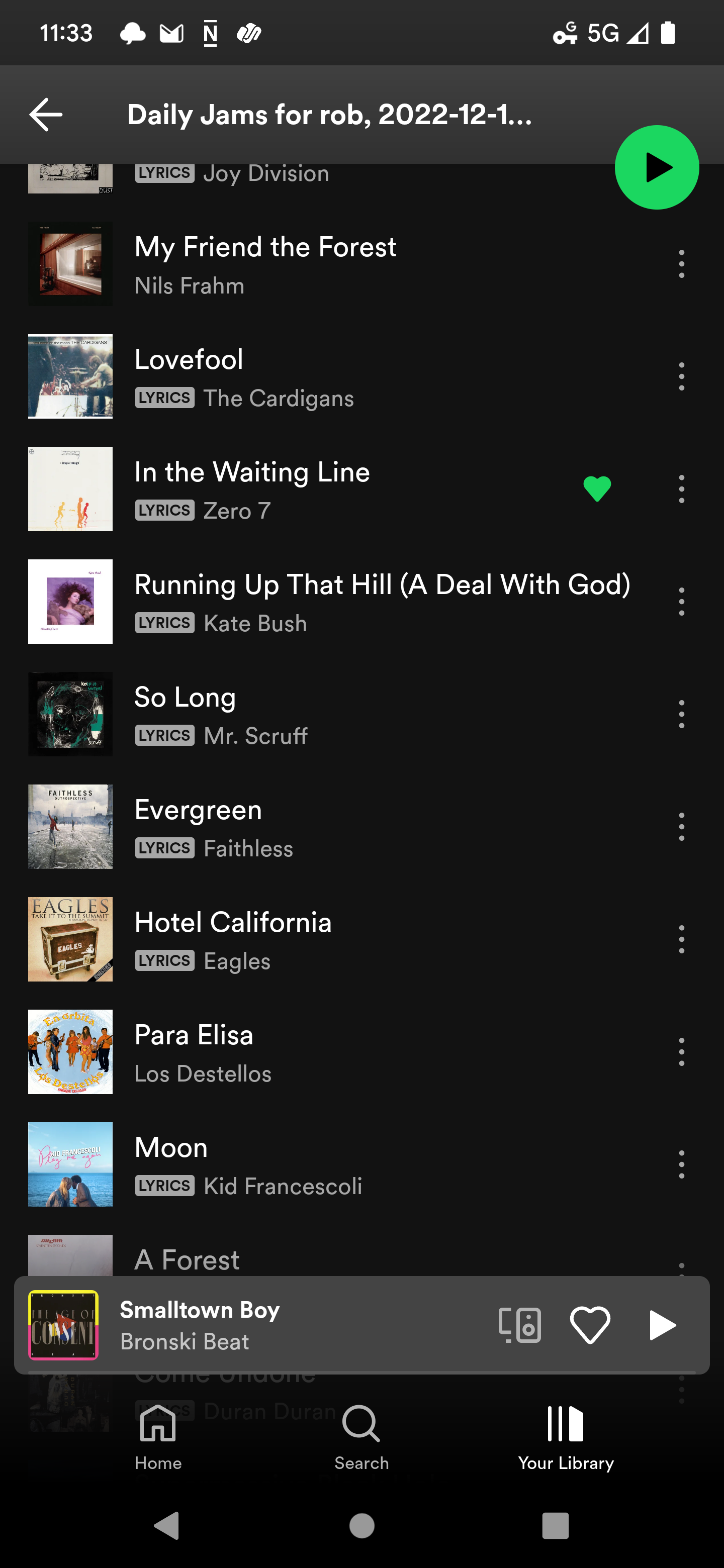
lucifer: it seems that me listening to my daily jams is totally absent from my listens. WTF?
lucifer
mayhem: uhh. weird... are other spotify listens present there?
mayhem
Yes, my album listens for when I am at my computer. But me listening on mobile seems to send listens.
lucifer
huh. can you try playing daily jams now? i'll query spotify api to check if the listens start to show up there or not.
mayhem
Playing now. Private listening is off, I checked.
lucifer
track playing is Röyksopp Forever?
schickling[m]
<lucifer> "schickling: we have a tool..." <- Got it. Thanks a lot for your explanation. Is the source code for this available somewhere? Curious to learn more!
Sophist-UK has quit
lucifer
schickling[m]: yes, but its spread in a lot of places. if you check back in some days, we have an open PR to document it.
the lookups are done against a typesense index. the index itself is keyed by `artist_name + track_name` of recordings.
schickling[m]
lucifer: Awesome! Looking forward to that!
I assume for the string comparison you use some kind of "distance" calculation? Curious which approaches you leverage for that.
lucifer
yes levensthein distance to evaluate the hits returned by the index lookup
we lookup in the typesense search index, the hits returned by the search index are then evaluated with the original search term based on levensthein distance.
schickling[m]
Got it! Thanks a lot for explaining. Will try to learn more about it :)
lucifer
based on the distance we assign the match a `quality`, high, medium, low.
cool, feel free to ping again if you want to ask anything else.
mayhem: 2 new listens just showed up for you.
schickling[m]
Thanks a lot lucifer! Appreciate it!
Together with a friend we've been exploring track matching approach as well. In case we have any new learnings, I'll share them if you're interested :)
lucifer
schickling[m]: mayhem designed the current system we use in LB. we also use a few other tricks for matching. you probably want to discuss your approach with him for insights.
as you may know, MB has multiple versions of the same recording/release. multiple release events of a recording being one factor in it. in that case you need a tie breaker to ensure that a given name always matches to a given recording for consistency.
Rishabh has quit
for that purpose we have the concept of canonical recordings/releases in LB.
schickling[m]
lucifer: Very interesting. How do you "pick" the canonical recording/release?
schickling[m] uploaded an image: (58KiB) < https://libera.ems.host/_matrix/media/v3/download/matrix.org/GqGIdmXwvDoJOkhQshACEFbn/CleanShot%202022-12-10%20at%2015.01.05%402x.png >
btw there's a funny bug (?) where the scale goes beyond 10/10
for similarity matching we only use latest year iirc so i would probably look at the this_year or last_year stats.
mayhem: the listens now do appear but running up that hill will still be in daily jams :(. because the version played on spotify is different from the one recommended by CF so filtering would not match.
i think we need to work on the idea to build another abstraction over canonical recordings for recommendation use cases.
fwiw, CF recommends `Running Up That Hill (A Deal With God)` whereas spotify plays `Running Up That Hill (A Deal With God) - 2018 Remaster`
{kind=link}