I stopped 5, I'll restart it once 4 recovered (if it does)
rimskii[m] joined the channel
rimskii[m]
<lucifer> "rimskii: hi! let me know when..." <- lucifer (IRC): hi! srry, i saw your message just now, was on flight.
is it okay if I will ask the questions here? :>
mayhem
yes
rimskii[m]: just ask questions; we may not answer immediately, but we do eventually. :)
zas
I stopped sir-prod for now
restarting solr 5
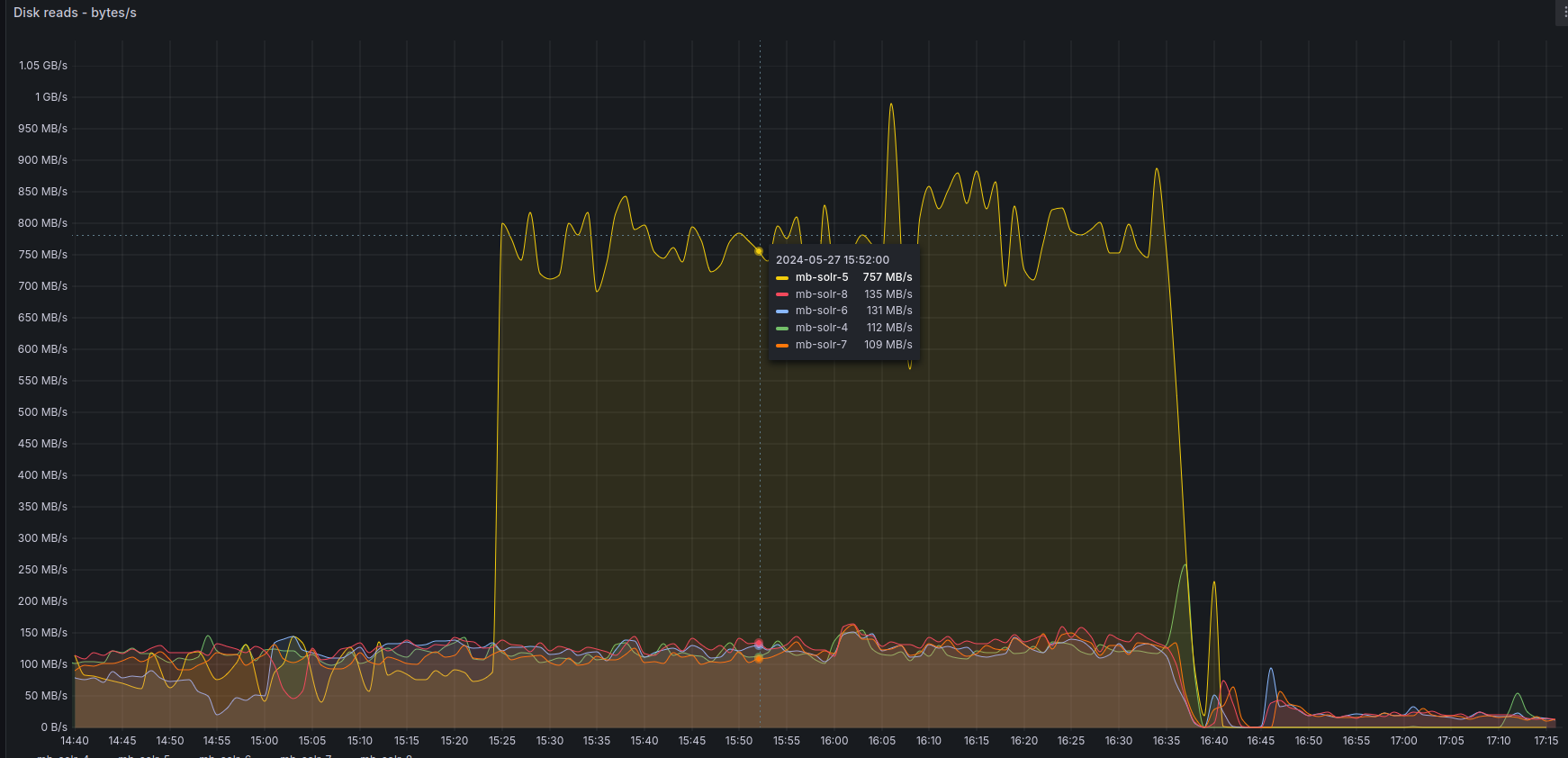
lucifer: the main question is why solr 5 eventually start to read from disk very heavily (like 800MB/s vs 50MB/s for others), when it does, the cluster crashes at some point, I think that's because solr5 gets very slow (load > 100) and it somehow cascades
lucifer (IRC): I'm setting up my stuff now. wanted to ask what about the apple music and soundcloud apis? I have an account to use soundcloud APIs, but not for the musickit one( also its paid. do we have a MB acc for it or should I buy it?
lucifer
rimskii[m]: we have an apple music developer token you should be able to use methinks.
rimskii[m]
cool !
zas
can it be an underlying hardware issue? I mean that's really weird it always happen on solr5 (and sometimes 4) but never on others
rimskii[m]
I think i will start from importing functions first (for Spotify, Soundcloud and apple music), then go to exports
zas
I could snapshot the vm, destroy it and recreate it while preserving IPs (I think)
but first let's see if lucifer can get something from logs
bumping the rate limit to 60 (from 20/s)
mayhem
monkey[m]: lucifer : do we know why the feed doesn't load?
zas: looks like memory issues. every 1s, GC activity is causing 0.3s stalls
zerodogg has quit
mayhem
aerozol had the same problem.
lucifer
rimskii[m]: i see, makes sense. i can help with it in a while.
rimskii[m]
okay, thanks!
lucifer
when that happens solr starts reading a lot of data from disks.
rimskii[m]
also if I want to PR should I first open a ticket for it? if the PR is related to GSoC. I would like to commits PR little by little
mayhem
rimskii[m]: we open tickets sometimes, but in a lot of cases they are not needed for ordinary PRs. I suspect that lucifer wants you to open a ticket, he'll ask you to do that.
.. *if* lucifer wants ....
zas
lucifer: by memory issues do you mean lack of RAM? or something else?
lucifer
zas: yes. RAM and JVM heap.
but still not sure why only on two particular nodes.
zas
perhaps they are slower than others (shared cpu) and it leads to the issue more quickly
or an underlying hardware issue leads to that
lucifer
possible yeah
zas
I think I'll rescale this server: it wil rule out an underlying hardware issue and give it more ram. Extra cost until we moved to new cluster though.
mayhem
fine.whatever.
zas
let's try
I'll stop solr5
pranav[m] joined the channel
pranav[m]
akshaaatt (IRC): if ur free post today’s dev meet id like to have a small brief meet re how to proceed with my GSoC project if that’s fine with u..
akshaaatt
Sure, pranav[m] !
lucifer
mayhem: i'll try to debug. sentry has been down for a few days so can't check ther.
zas
solr5 has twice more cores now, but I couldn't get more RAM. Though underlying hardware changed at least. I'll slowly set the rate limit back to normal
mayhem
ok, no rush I would say. not sure how many people use that page.
lucifer
can you try loading it now?
(no fixes just to see if something is logged in prod)
pranav[m]
lucifer (IRC): for a project of mine that I have to make for my college, I had a doubt re pagination from backend. I have let’s say 10,000-15,000 entries and am using page number pagination.. what shud be my page size and how is it determined in order for the server to not slow down
pranav[m]: no fixed rule for that, depends on what database you are using, how your data is structured, how often data is retrieved and lots of other factors.
probably start so that most common cases are covered in 1 api call. if that is too much then decrease the page count.
but to be honest, most applications never reach that scale that you need to worry about such things.
pranav[m]
Okay, thanks a lot lucifer_ (IRC) will keep this in mind
lucifer
rimskii[m]: PRs are fine. tickets are not really required in most cases but if you like to create some structure or etc. feel free to.
lucifer for the troi part. https://github.com/metabrainz/troi-recommendation-playground/blob/main/troi/tools/spotify_lookup.py
this is an example of how we export playlists from LB to spotify. you can create a similar function here that imports playlists from spotify to LB.
most of the code you have in LB server should remain the same just live in this repo instead.
btw, solr cluster is back, new solr5 has twice cores, so it handles twice more requests than others, everything is back to normal
lucifer
rimskii[m]: you can finish moving the spotify import for now. i'll look into soundcloud apis and let you know how we should proceed
zas
twodoorcoupe: if you have any question about Picard, feel free to ask.
twodoorcoupe
zas: thank you, I saw you have been doing a ton of refactoring lately
rimskii[m]
<lucifer> "rimskii: you can finish moving..." <- okay, thanks a lot! ll let you know once I finish or mybe need a help xd
lucifer
sure sounds good
zas
Yes, we are heading towards Picard3 and there were a lot of things we couldn't do before without breaking too much stuff
Picard3 will come with new plugin system and so compatibility will be broken anyway. outsidecontext is also experimenting moving to PySide6.
twodoorcoupe
zas: I was planning to use extension points for registering processing functions. If that is bound to change I can modify it later on
zerodogg has quit
zas
The main change is we'll make plugin accessible extension points much more obvious, and we'll provide a "plugin API" to guarantee access to Picard internals.
relaxoMob joined the channel
In the past, maintaining plugins compat was always a bit of a problem, because plugins were accessing the Picard code freely. It will be still possible (that's Python), but if we break something not part of the "official" plugin API it'll be not our problem ;)
Basically every patch had an underlying question: does it break one plugin? -> look for plugins code, etc... kinda impossible to manage with a growing list of plugins
For your GSoC project, I think you can work on a PR over Picard code, without bothering plugins side while keeping in mind it will be a plugin at the end.
The new plugin system should be out (I hope) before end of GSoC. I'll focus on it once the cleanup work will be done.
twodoorcoupe
Makes sense, thank you. Do you and outsidecontext prefer to see a pr for each feature added, let's say each week, or a larger one every once in a while?
Great, I had already planned to work on plugins side in the final weeks
zas
We usually prefer to follow devel steps, so opening a draft PR early is often better: we can review and give you feedback along the way
outsidecontext
hi
zas
Hey outsidecontext
twodoorcoupe
Ok, will do
outsidecontext
twodoorcoupe: ideal would be multiple PRs, but for parts that make sense individually. doesn't need to be exactly weekly or such.
zas
yes, subdivide your work in small reviewable bits
outsidecontext
and you can open PRs already early as soon as you think there is something to discuss. Mark the PR as a draft and we can have an active discussion on anything
twodoorcoupe
Perfect
outsidecontext
we currently had multiple of those due to zas' many refactorings :)
mayhem
<BANG>
hello everyone. I'm a poor excuse for the usual spaniard running the show!
Last week mostly played around with feed generation in Python with my feed reader. Found that Payoneer blocked me for not using Gmail during registration and luckily I fixed it :)
And finally JadeBlueEyes:
Nothing much from me from last week! I've been very busy with exams, but I've only got three more to go this week!
After that, I'll work on setting up a local mock for testing sending emails
That was it for mailed in reviews, lets jump to reviews for the rest of us.
Also worked on SIR testing and Solr 9.6 update, upgraded the wiki server to Noble, plus some support and tickets triage.
Good luck to the IA!
Fin, go atj?
atj
hello
Last week I continued testing and tweaking the new Solr cluster. I configured ZooKeeper ACLs, wrote some scripts to try and balance leaders across the nodes in the cluster, improved the Ansible role and started working on documentation.
I also worked with yvanzo to prepare the cluster for use as the search provider on beta.
and bootstrapped the new Matrix server, and assisted lucifer in setting up Borg backups.
that's all I can remember at this point! lucifer?
lucifer
sure sounds good!
hi all!
last week, i worked on setting up chatbrainz, participated in the gsoc intro meeting, worked on existing LB PRs to fix dump issues, and speedup imports in spark.
also worked on exploring setting up spark cluster with ansible and some misc LB bugs.
that's it for me. mayhem next?
mayhem
hey o
Annoying week, dealing with lots of stupid stuff. like Hetzer abuse BS -- more on that during that topic meeting.
I worked a bit on JSPF cleanup, since we identified a few ways in which we didn't meet the spec.
Had two conference calls, one with researchers who are investigating the fairness of recommendation engines and they are
interesting in working on that with us -- which is quite interesting. The other call was the GSoC welcome meeting which is all around lovely.
This week I've got lots of small stuff to look after and then I can finally dig back into LB Local.
fin. twodoorcoupe go!
twodoorcoupe
hello folks!
last week I finished preparing drafts for my gsoc project
started working on filtering out cover art images by size
{kind=link}
{kind=link}