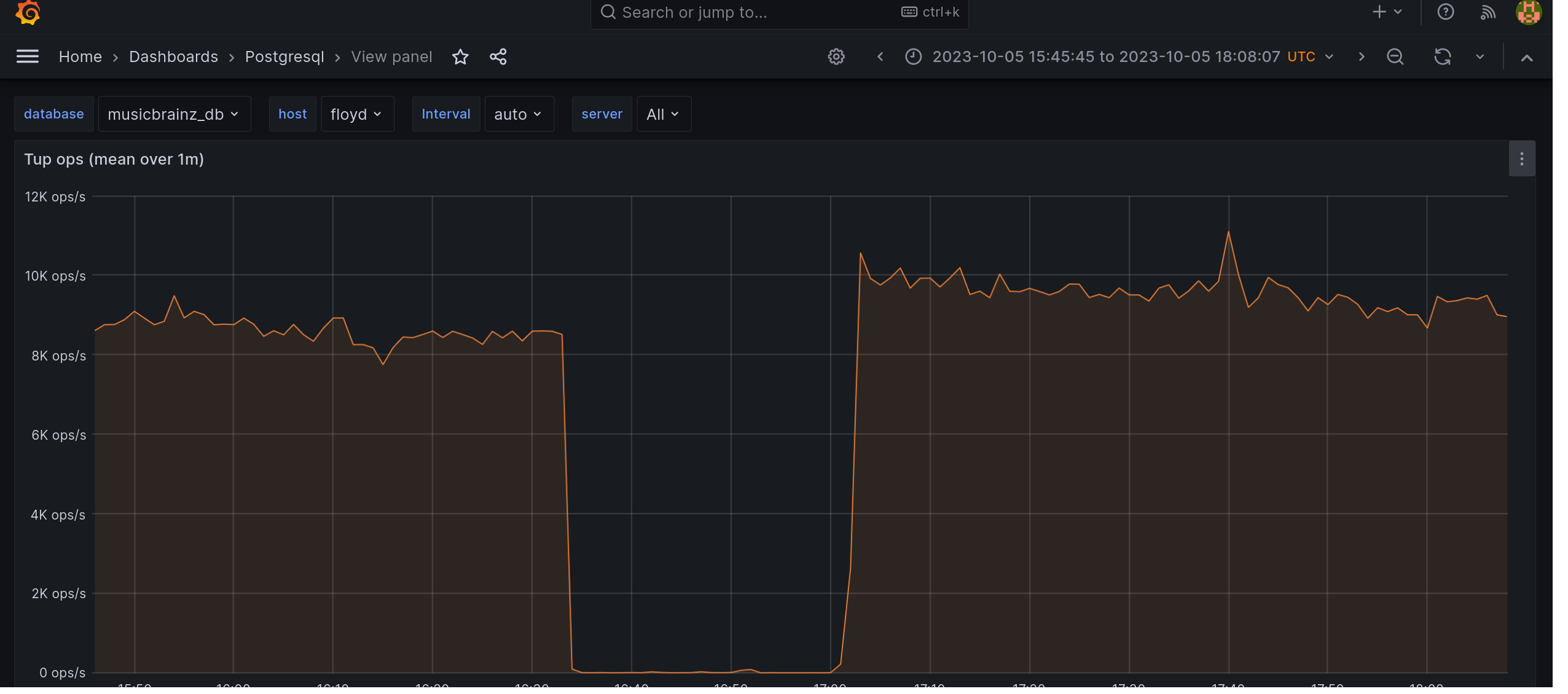
zas: there's not much info in pg logs other than that checkpoints were occurring too frequently (usually indicating heavy writes)
however the load averages on wolf and the spark cluster nodes were higher than usual during the same time frame, so perhaps something heavy was being processed there
mayhem: we can do that yes but we won't be able to join that with any of our other data then.
i guess it would be fine to store the mb_metadata_cache but it wouldn't lower the load on MB db because all the data is still read from there.
imo we need to full proof the incremental updates so that we can totally get rid of the bulk generate from scratch.
bitmap
can you use unlogged tables? that would solve the wal accumulation issues. (you won't be able to query the tables from a standby though, you'll have to use the master)
zas
also Jackson5 were clearly active during the time floyd was under load, so this has to be checked too
lucifer
bitmap: that should be possible i guess. will need to check why so much wal accumulated though. we don't write back much, just read a lot.
mayhem
lucifer: yes, to all that. the inability to do joins limits what we can do, but I think there are many datasets that we envision hosting with DSH-on-spark could actually be handled by couchdb. mb metadata may not be the best example. but something like last_listened_at for all users could.
lucifer
mayhem: yes that makes sense
mayhem
and on making the cached data incremental updates work -- we'll have a chance to look at that real soon. joy.
mayhem: I cannot find mine D: did you find a random L shirt laying about in the office any of these days? 😅
(I will be at the office in 30)
mayhem makes he L gesture on his forehead
lusciouslover has quit
I mean, if that gets me a t-shirt again, I'll take the L
reosarevok hides
mayhem
outsidecontext: error handling has been fixed now on the DSH endpoint.
outsidecontext
mayhem: will check in a minute
mayhem
now to actually work on why some bits dont return data.
yvanzo: ping
outsidecontext
curl -X POST -k -H 'Content-Type: application/json' -i 'https://labs.api.listenbrainz.org/mbid-mapping-release/json' --data '[{"[artist_credit_name]": "Paradise Lost", "[recording_name]": "Paradise Lost", "[release_name]": "Drown in Darkness \\u2013 The Early Demos"}, {"[artist_credit_name]": "Paradise Lost", "[recording_name]": "Paradise Lost (live)", "[release_name]": "Drown in Darkness \\u2013 The Early Demos"},
see the query that outsidecontext posted above. that is against the mapping with releases endpoint.
can you plz take a look at that if you have a moment?
monkey
mayhem: pushed, should be fixed now
outsidecontext
lucifer: all the requested tracks are supposed to yield a result as there is a recording for it. but recording name equals band name. I can reliably reproduce the issue with this endpoint
lucifer
mayhem, outsidecontext: sure looking into it
mayhem
thx monkey
thx lucifer
lucifer
what branch is it running on?
mayhem
thats on labs, no? should be current prod more or less.
Both to keep us on track/as a handy reminder, and to keep the community and those who couldn’t make it in the loop ➰
monkey
mayhem: Looks like the error is related to the manifest file we write to disk (so that flask knows which javascript file to load). I don't think we changed anything, so that's surprising
{kind=link}
{kind=link}